Artikel ini akan membahas tentang cara mendapatkan informasi keterhubungan objek entitas antar artikel serta klasifikasi sentimen artikel. Bertujuan untuk menampilkan hasil sentimen positif atau negatif seorang tokoh berdasarkan graf keterkaitan antar entitas objek pada sekumpulan artikel sehingga membuktikan bahwa bahwa semakin banyak hubungan seorang tokoh antar objek entitas maka hasilnya sentimennya dapat positif atau negatif. Untuk mendapatkan keterhubungan objek entitas antar artikel dengan menggunakan teknik Named Entity Recognition dan visualisasinya menggunakan graph sedangkan proses klasifikasi menggunakan Naive Bayes Classifier. Artikel yang akan digunakan membahas tentang pemain sepakbola yang bermain untuk klub Real Madrid yaitu Crtistiano Ronaldo dengan jumlah total 11 berita. Pengerjaan cara selengkapnya serta metode yang digunakan dibahas di bawah ini.
1. Named Entity Recognition
Merupakan suatu bagian dari ekstraksi informasi pada suatu artikel. Bertujuan untuk mendeteksi suatu entitias berupa nama,organisasi, lokasi, alamat email dan lainnya sesuai dengan keperluan. Contohnya “Kecelakaan pada pukul 21.00 di Jln. Braga No.21”. Dengan melakukan proses Named Entity Recognition didapatkan Jln. Braga bertipe lokasi. Dari proses tersebut terlihat fungsi Named Entity Recognition mendeteksi kata atau kempulan kata yang merupakan entitas lalu dikategorikan ke dalam tipe yang sesuai untuk dapat diolah. Sumber : “https://yudiwbs.wordpress.com/2012/02/07/named-entity-recognition/”.
Pada artikel ini akan membahas tentang cara untuk mevisualisasikan keterkaitan antar artikel berdasarkan hasil dari banyaknya kemunculan suatu objek berupa nama orang, lokasi, organisasi, persen, dan uang dari hasil Named Entity Recognition secara berurutan. Misalkan kata Ronaldo dan muncul setelah kata Real Madrid dalam 5 kali urutan kemudian setelah visualisasi ternyata memiliki hubungan keterkaitan yang sangat kuat.
Langkah untuk mendapatkan visualisasi harus melalui proses Named Entity Recognition menggunakan bahasa pemrograman Python karena memiliki library Natural Language Toolkit yang mendukung dalam proses mendapat objek entitas sehingga dapat diperoleh Named Entity Recognition. Caranya yaitu :
- Tentukan berita yang akan dipilih.
Berita yang dipilih yaitu mengenai pemain sepakbola Cristiano Ronaldo sejumlah 11 artikel.
- Buat Program untuk ekstraksi informasi
Dengan menggunakan bahasa pemrograman python lakukan impor library re untuk melakukan ekstrak informasi berupa email dan nomor telepon karena dapat mengenali karakter unik dari suatu kalimat seperti @ serta aturan penulisan nomor yang dapat dijumpai pada email dan penulisan nomor telepon internasional aturan karakter yang ditetapkan. Kemudian lakukan impor library nltk untuk dapat melakukan proses tokenisasi, pembersihan stopwords, tagging pengelompokkan kata, chunking. Sehingga dapat muncul hasil entitas objek yang diambil. Contoh impor library terdapat pada gambar di bawah ini.
Gambar 1 : impor library.
Kemudian buat variabel untuk dapat membuka artikel.

Gambar 2 : deklarasi variabel untuk baca artikel.
Lalu buat fungsi untuk dapat melakukan tahapan preprocessing data artikel seperti terlihat pada gambar di bawah ini.

Gambar 3 : fungsi preprocessing
Gambar di atas menjelaskan tahapan preprocessing artikel yaitu tahap tokenisasi untuk dapat mengambil kata-kata yang penting pada artikel dan membuang kata-kata penghubung seperti and, or, the, after dan sebagainya karena artikel yang digunakan memakai bahasa inggris lalu tahap selanjutnya yaitu tagging yaitu mencocokan tag kata apakah termasuk ke dalam subjek, objek, atau predikat hal ini akan sangat bermanfaat ketika masuk dalam tahapan chunking. Selanjutnya buat fungsi untuk dapat mengambil nomor telepon dan alamat email seperti pada gambar di bawah ini.

Gambar 4 : fungsi ambil nomor telepon dan alamat email.
Kedua fungsi yang terdapat pada gambar di atas menggunakan library re yaitu berguna untuk dapat mengambil sejumlah karakter unik yang terdapat pada artikel seperti contohnya nomor telepon, kode pos, alamat email. Tahapan selanjutnya yaitu mengambil lokasi pada artikel seperti pada gambar di bawah ini.

Gambar 5 : fungsi ambil lokasi
Tahapan gambar di atas :
- Buat variabel array lokasi
Atur isinya kosong supaya dapat menampung hasil lokasi yang muncul dalam artikel.
- Buat variabel kalimat untuk panggil fungsi preprocessing
Berfungsi untuk dapat memanggil hasil preprocessing artikel untuk selanjutnya dapat masuk ke dalam tahap chunking.
- Buat proses chunking
Buat variabel tagged_sentence Lakukan perulangan dengan tipe for-loop sepanjang variabel kalimat yang sudah melalui proses preprocessing lalu buat variabel chunk lakukan hal yang sama namun perulangan sepanjang variabel tagged_sentence yaitu kalimat telah diberikan tag dengan memanggil nltk.ne_chunk yang berfungsi untuk dapat menemukan hasil penguraian kata menggunakan struktur pohon Tree. Kemudian buat struktur pemilihan untuk dapat menemukan tipe yang dibutuhkan yaitu Tree hasil penguraian dengan cara memanggil library nltk.tree.Tree jika berhasil buat kembali struktur pemilihan untuk dapat menemukan label hasil penguraian dalam bantuk Tree karena yang ingin diambil yaitu kata yang berhubungan dengan lokasi maka label yang dipilih yaitu LOCATION lalu jika ditemukan masukan label menggunakan fungsi append() supaya dapat ditampung ke dalam array lokasi. Hasil akhirnya return semua lokasi yang didapatkan dari hasil chunking.
Setelah tahap pengambilan lokasi lakukan kegiatan serupa untuk pengambilan nama, organisasi, persen, uang dalam sebuah artikel namun yang membedakan adalah label yang digunakan seperti contohnya pada 4 gambar di bawah ini.

Gambar 6 : fungsi ambil nama

Gambar 7 : fungsi ambil organisasi

Gambar 8 : fungsi ambil persen.

Gambar 9 : fungsi ambil uang.
Tahap selanjutnya yaitu membuat variabel yang digunakan untuk dapat menampilkan hasil pengambilan entitas objek lalu tampilkan menggunakan perintah print seperti pada contoh 2 gambar di bawah ini.

Gambar 10 : deklarasi variabel tampilkan entitas objek.
Gambar 11 : perintah tampilkan hasil entitas objek.
Jalankan program lalu hasil yang didapat seperti pada gambar di bawah ini.

Gambar 12 : Hasil ekstak/pengambilan objek entitas.
Kemudian lakukan cara yang sama untuk 10 artikel lainnya yang membahas tentang Cristiano Ronaldo. Hasil keleuruhan dari ekstraksi informasi menghasilkan urutan sebagai berikut :
1. telepon
2. email
3. nama
4. organisasi
5. lokasi
6. persen
7. uang
Dimana hasil untuk 11 file seperti ini :
hasil file 1
[]
[]
['Barcelona', 'Lionel Messi', 'Cristiano Ronaldo', 'Clasico XI', 'Pinto', 'Jose Mourinho', 'Pepe', 'Pepe', 'Pinto', 'Catalunya', 'Brazilian', 'Pablo Garcia', 'Lee Carsley', 'Drenthe', 'Rabbit', 'Barcelona', 'River Plate']
['Real', 'Bernabeu', 'LEAST', 'Real Madrid', 'Bernabeu', 'Real Madrid', 'Arsenal', 'Barcelona', 'Rubin Kazan', 'Sevilla', 'Osasuna', 'Everton', 'Real Madrid', 'European', 'Real Madrid', 'Bernabeu', 'Sevilla', 'Real Madrid']
['West Ham']
[]
[]
hasil file 2
[]
[]
['Cristiano Ronaldo', 'Taylor Swift', 'Selena Gomez', 'Ariana Grande', 'Instagram', 'Ronaldo', 'Cristiano Ronaldo', 'Bayern Munich', 'Thomas Muller', 'Muller', 'Bayern', 'Ronaldo', 'Ronaldo', 'Lionel Messi', 'Muller']
['Real Madrid', 'Real Madrid', 'Portugal', 'Lionel Messi', 'Real Madrid', 'Champions League', 'Real Madrid', 'Juventus', 'Lionel Messi']
['Bayern Munich']
[]
[]
hasil file 3
[]
[]
['Cristiano Ronaldo', 'Florentino Perez', 'Ronaldo', 'Champions League']
['Real', 'Atletico', 'LaLiga', 'Champions League', 'Santiago Bernabeu', 'Champions League', 'Real Madrid']
[]
[]
[]
hasil file 4
[]
[]
['Cristiano Ronaldo', 'Vicente Calderon Stadium', 'Cristiano Ronaldo', 'Real', 'Toni Kroos', 'Vazquez', 'Casemiro', 'Ronaldo', 'Jan Oblak', 'Dani Carvajal', 'Karim Benzema', 'Zidane', 'Zinedine Zidane']
['AP', 'Real Madrid', 'Champions League', 'Real Madrid', 'Atletico Madrid', 'Santiago Bernabeu', 'Atletico', 'Real Madrid', 'Bernabeu', 'Champions']
[]
[]
[]
hasil file 5
[]
[]
['Cristiano', 'Ronaldo', 'Atletico', 'Ronaldo', 'Ronaldo', 'Real', 'Real']
['Real Madrid', 'Real', 'Bernabeu', 'MEGA', 'Vicente Calderon']
[]
[]
[]
hasil file 6
[]
[]
['Zinedine', 'Granada', 'Granada', 'Zidane', 'Barcelona', 'Barcelona', 'Zidane', 'Granada', 'Zidane', 'Atletico Madrid', 'Madrid', 'Granada', 'Cristiano Ronaldo', 'Zidane', 'Zidane']
['Real Madrid', 'Zidane', 'Real Madrid', 'Cam Nou', 'Granada', 'Champions League', 'Santiago Bernabeu Stadium']
[]
[]
[]
hasil file 7
[]
[]
['Ronaldo', 'Atletico', 'Ronaldo', 'Raul', 'Ronaldo', 'Tottenham Hotspur', 'Jimmy', 'Ronaldo', 'Alfredo Di Stefano', 'Ronaldo', 'Ferenc Puskas', 'Ronaldo', 'Iker Casillas', 'Ronaldo', 'Messi', 'Ronaldo', 'Messi', 'Ivan Zamorano', 'Ali Daei', 'Lionel', 'Ronaldo']
['Real Madrid', 'Manchester United', 'Real', 'Lionel Messi', 'Real Madrid', 'Manchester United', 'Real Madrid', 'Champions League']
[]
[]
[]
hasil file 8
[]
[]
['El Clasico', 'Barcelona', 'Barcelona', 'Juventus', 'Luis Su\xc3\xa1rez', 'Luis Enrique', 'Bayern Munich', 'Cristiano', 'Ronaldo', 'Marcelo', 'La Liga', 'Barca', 'Luis Enrique', 'Neymar', 'Neymar', 'Zinedine Zidane', 'Gareth Bale', 'Ronaldo']
['Real Madrid', 'Santiago', 'Madridistas', 'Catalan', 'Champions League', 'Houdini', 'Lionel Messi', 'Barcelona', 'Champions League', 'La Liga']
[]
[]
[]
hasil file 9
[]
[]
['Barcelona', 'Lionel Messi', 'Cristiano Ronaldo', 'Clasico XI', 'Pinto', 'Jose Mourinho', 'Pepe', 'Pepe', 'Pinto', 'Catalunya', 'Brazilian', 'Pablo Garcia', 'Lee Carsley', 'Drenthe', 'Rabbit', 'Barcelona', 'River Plate']
['Real', 'Bernabeu', 'LEAST', 'Real Madrid', 'Bernabeu', 'Real Madrid', 'Arsenal', 'Barcelona', 'Rubin Kazan', 'Sevilla', 'Osasuna', 'Everton', 'Real Madrid', 'European', 'Real Madrid', 'Bernabeu', 'Sevilla', 'Real Madrid']
['West Ham']
[]
[]
hasil file 10
[]
[]
['Tonight', 'Barcelona', 'Clasico', 'Cristiano', 'Neymar', 'Bale', 'Barcelona', 'Jose Manuel Pinto Pinto', 'Pinto', 'Right', 'Julien Faubert', 'Faubert', 'Real', 'Madrid', 'Jermaine Pennant', 'Aaron', 'Jonathan Woodgate Injuries', 'Los Blancos', 'Jonathan Woodgate', 'Centre', 'Thomas Vermaelen', 'Vermaelen', 'Back', 'Dmytro Chygrynskiy', 'Chygrynskiy', 'Chygrynskiy', 'Alexander Hleb', 'Hleb', 'Barca', 'Birmingham', 'Wolfsburg', 'Centre Midfield', 'Thomas Gravesen Along', 'Julien Faubert', 'Everton', 'Thomas', 'Centre Midfield', 'Fabio', 'Barcelona', 'Fabio Rochemback', 'Left', 'Royston Drenthe', 'Royston Drenthe', 'Madrid', 'Drenthe', 'Julio Baptista', 'Julio', 'Baptista', 'Sevilla', 'La Liga', 'Maxi', 'Maximiliano Maxi Gaston Lopez', 'Lopez']
['Real Madrid', 'Real Madrid', 'Ronaldo', 'Lionel Messi', 'Real Madrid', 'Real Betis', 'Catalan', 'Champions League', 'Real Madrid', 'Woodgate', 'Real Madrid', 'Real', 'Arsenal', 'Roma', 'Shakhtar Donetsk', 'Shakhtar', 'Arsenal', 'Arsenal', 'Camp Nou', 'Stuttgart', 'Real Madrid', 'Real', 'Barca', 'Feyenoord', 'European', 'Real', 'Real Madrid', 'Real Madrid', 'FC Moscow']
['West Ham', 'North East']
[]
[]
hasil file 11
[]
[]
['Cristiano Ronaldo', 'Vicente Calderon Stadium', 'Cristiano Ronaldo', 'Real', 'Toni Kroos', 'Vazquez', 'Casemiro', 'Ronaldo', 'Jan Oblak', 'Dani Carvajal', 'Karim Benzema', 'Zidane', 'Zinedine Zidane', 'Tonight', 'Barcelona', 'Clasico', 'Cristiano', 'Neymar', 'Bale', 'Barcelona', 'Jose Manuel Pinto Pinto', 'Pinto', 'Right', 'Julien Faubert', 'Faubert', 'Real', 'Madrid', 'Jermaine Pennant', 'Aaron', 'Jonathan Woodgate Injuries', 'Los Blancos', 'Jonathan Woodgate', 'Centre', 'Thomas Vermaelen', 'Vermaelen', 'Back', 'Dmytro Chygrynskiy', 'Chygrynskiy', 'Chygrynskiy', 'Alexander Hleb', 'Hleb', 'Barca', 'Birmingham', 'Wolfsburg', 'Centre Midfield', 'Thomas Gravesen Along', 'Julien Faubert', 'Everton', 'Thomas', 'Centre Midfield', 'Fabio', 'Barcelona', 'Fabio Rochemback', 'Left', 'Royston Drenthe', 'Royston Drenthe', 'Madrid', 'Drenthe', 'Julio Baptista', 'Julio', 'Baptista', 'Sevilla', 'La Liga', 'Maxi', 'Maximiliano Maxi Gaston Lopez', 'Lopez', 'Ronaldo', 'Atletico', 'Ronaldo', 'Raul', 'Ronaldo', 'Tottenham Hotspur', 'Jimmy', 'Ronaldo', 'Alfredo Di Stefano', 'Ronaldo', 'Ferenc Puskas', 'Ronaldo', 'Iker Casillas', 'Ronaldo', 'Messi', 'Ronaldo', 'Messi', 'Ivan Zamorano', 'Ali Daei', 'Lionel', 'Ronaldo']
['AP', 'Real Madrid', 'Champions League', 'Real Madrid', 'Atletico Madrid', 'Santiago Bernabeu', 'Atletico', 'Real Madrid', 'Bernabeu', 'Champions', 'Real Madrid', 'Real Madrid', 'Ronaldo', 'Lionel Messi', 'Real Madrid', 'Real Betis', 'Catalan', 'Champions League', 'Real Madrid', 'Woodgate', 'Real Madrid', 'Real', 'Arsenal', 'Roma', 'Shakhtar Donetsk', 'Shakhtar', 'Arsenal', 'Arsenal', 'Camp Nou', 'Stuttgart', 'Real Madrid', 'Real', 'Barca', 'Feyenoord', 'European', 'Real', 'Real Madrid', 'Real Madrid', 'FC Moscow', 'Real Madrid', 'Manchester United', 'Real', 'Lionel Messi', 'Real Madrid', 'Manchester United', 'Real Madrid', 'Champions League']
['West Ham', 'North East']
[]
[]
Dari 11 artikel hanya tampil nama dan organisasi yang didapatkan namun ada beberapa artikel yang mendapatkan hasil lokasi. Karena fokus dari artikel ini adalah tentang Cristiano Ronaldo maka informasi yang akan ditampilkan dalam Graph adalah seberapa banyak dia disebut bersamaan dengan pemain atau pelatih atau klub atau entitas objek lainnya secara bersamaan dalam satu kali perulangan/ekstraksi informasi.Setelah membuat program ekstraksi informasi maka masuk tahap ketiga yaitu buat program untuk menampilkan Graph hubungan antar entitas objek pada 11 artikel dimana simpul adalah entitas objek dan edges adalah jumlah kemunculan 2 entitas objek yang didapat/disebut secara bersamaan.
- Buat program untuk menampilkan Graph hubungan antar entitas objek pada 11 artikel.
Lakukan impor library networkx untuk menampilkan garis penghubung antar simpul lalu impor library matplotlib untuk menampilkan grafik Graph seperti pada gambar di bawah ini.

Gambar 12 : impor library networkx & matplotlib.
Selanjutnya buat fungsi untuk dapat menampilkan graf, langkah untuk menampilkan graf adalah sebagai berikut :
- Buat variabel untuk deklarasi Graph.
Tanpa adanya variabel deklarasi Graph maka tidak akan dapat dibuat sebuah Graph. Kemudian tambahkan fungsi untuk dapat menambah edges dari graph menggunakan library networkx kemudian buat variabel untuk dapat mengatur pewarnaan,ukuran tulisan,ukuran simpul, jenis font, warna edges, lebar garis edges.seperti pada gambar di bawah ini.
Gambar 13 : deklarasi variabel untuk tampilkan Graph.
- Atur tampilan Graph.
Kemudian atur penampilan edges,simpul, dan ukuran label seperti contoh pada gambar di bawah ini.
Gambar 14 : Atur tampilan Graph.
- Atur label jumlah kemunculan entitas objek pada Graph.
Berfungsi untuk menampilkan jumlah kemunculan 2 objek entitas yang didapat secara bersamaan saat tahap ekstraksi informasi. Cara memasukannya untuk saat ini masih menggunakan cara manual dimana hasil kemunculan entitas objek ditulis ke dalam program untuk menampilkan Graph contohnya dari 11 artikel nama Cristiano Ronaldo dan Real Madrid muncul bersamaan sebanyak 6 kali maka ditulis seperti ini ('Cristiano Ronaldo','Real Madrid'): 6. Contoh lengkapnya seperti pada gambar di bawah ini.

Gambar 15 : Atur label jumlah kemunculan entitas objek.
- Atur jaringan antar simpul
Cara yang dilakukan mirip dengan sebelumnya namun tidak memerlukan label kemunculan. Contohnya seperti pada gambar di bawah ini.

Gambar 16 : Atur jaringan antar simpul.
- Jalankan program
Hasil yang didapat seperti pada gambar di bawah ini.
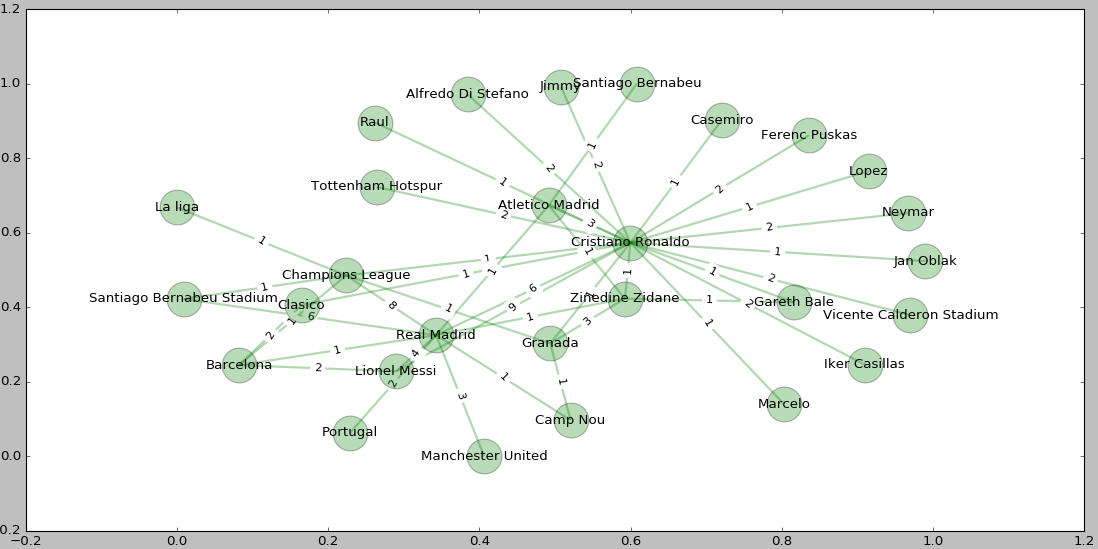
Gambar 17 : Graph hubungan antar entitas objek pada 11 artikel.
Terlihat pada gambar di atas entitas objek Cristiano Ronaldo memiliki hubungan yang sangat kuat terutama pada Lionel messi, Champions League, dan Real Madrid walaupun begitu tetap Cristiano Ronaldo memiliki hubungan tak langsung dengan sisa entitas objek seperti Manchester United. Setelah ditampilkan Graph kita perlu mencari tahu apakah hasil sentimen dari seorang Cristiano Ronaldo positif atau negatif karena memiliki hubungan keterkaitan dengan banyak entitas objek.
2. Naive Bayes Classifier.
“Naïve Bayes Classifier (NBC) merupakan sebuah pengklasifikasi probabilitas sederhana yang mengaplikasikan Teorema Bayes dengan asumsi ketidaktergantungan (independent) yang tinggi.
Keuntungan penggunan NBC adalah bahwa metode ini hanya membutuhkan jumlah data pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian. Karena yang diasumsikan sebagai variable independent, maka hanya varians dari suatu variable dalam sebuah kelas yang dibutuhkan untuk menentukan klasifikasi, bukan keseluruhan dari matriks kovarians.
Secara garis besar model NBC adalah sebagai berikut :
Atau dengan kata lain persamaan di atas dapat digambarkan sebagai berikut :
Kita akan mengklasifikasikan suatu dokumen berdasarkan isi atau kata-kata yang ada dalam dokumen tersebut. Sebagai contoh adalah apakah sebuah dokumen tersebut merupakan dokumen terkait bidang pendidikan atau tidak.
Untuk itu, kita bayangkan bahwa sebuah dokumen-dokumen diambil dari suatu kelas dokumen (class of document) yang dapat dimodelkan sebagai sebuah himpunan kata-kata, dimana probabilitas (independent) bahwa suatu kata ke-i dalam suatu dokumen terdapat dalam sebuah dokumen yang berasal dari class C. Hal tersebut dapat digambarkan dengan:
(Atau untuk memudahkannya dapat kita asumsikan bahwa probabilitas suatu kata dalam suatu dokumen adalah independen terhadap ukuran suatu dokumen, atau dengan kata lain semua dokumen diasumsikan berukuran sama.)
Selanjutnya probabilitas bahwa sebuah dokumen D, terhadap class C adalah:
Pertanyaannya adalah “Berapa probabilitas suatu dokumen D merupakan milik suatu class C?” atau dengan kata lain adalah berapa nilai probabilitas ?
Berdasarkan aksioma probabilitas:
dan
Selanjutnya Teorema Bayes digunakan untuk memanipulasi pernyataan probabilitas tersebut diatas menjadi sebuah terminologi likelihood / kemiripan:
Untuk menjawab permasalahan sebelumnya diatas, maka kita asumsikan bahwa hanya terdapat dua kelas, yaitu kelas Spam (S) dan Bukan Spam (~S). Dengan demikian model dapat digambarkan menjadi:
Dari Teorema Bayes tersebut diatas, dapat kita tuliskan menjadi:

Dengan membagi satu dengan yang lainnya dapat kita gambarkan menjadi:

Model tersebut dapat di-refactor-kan menjadi:

Akhirnya, rasio probabilitas dari p(S | D) / p(¬S | D) dapat diekspresikan dalam suatu terminologi series of likelihood-ratio / rasio kemiripan beruntun.
Selanjutnya, probabilitas aktual dari p(S | D) dapat dengan mudah dihitung melalui log (p(S | D) / p(¬S | D)), berdasarkan pernyataan bahwa p(S | D) + p(¬S | D) = 1.
Dengan mengambil logaritma dari keseluruhan rasio tersebut, maka kita dapatkan:

(teknik menggunakan log likehood / kemiripan logaritma ini sangat umum digunakan digunakan dalam statistik).
Akhirnya, dokumen dapat diklasifikasikan sebagai berikut.
Dokumen tersebut merupakan Spam apabila :
Dan sebaliknya apabila < 0, maka dokumen tersebut Bukan Spam.”
Contoh kerja metode Naive Bayes secara manual misalnya dari total dokumen terdapat 3 dokumen positif dan 4 dokumen negatif kemudian tambahkan nilai 1 (proses smoothing) setiap dokumen sehingga :
• Positif dokumen = 3 +1 = 4
• Negatif dokumen = 2 +1 = 3
• Total 4 + 3 = 7
Kemudian positif dokumen dibagi dengan total sehingga 4 / 7 dan untuk negatif 3 / 7.
Dari hasil penelusuran dokumen terdapat 2 kelas pada data training yaitu positif dan negatif. Dalam kelas positif dan negatif terdapat 8 kata yang sudah melalui proses tokenisasi karena ini bertujuan untuk menghitung semua jumlah kata maka diperlukan proses smoothing dengan cara jumlah kemunculan kata ditambah dengan 1 sehingga menjadi seperti berikut ini :
Ø Positif :
1. Best = 2 + 1 =
|
3 = 1/ 15
|
2. Well = 1 + 1 =
|
2 = 1/15
|
3. Good = 1 + 1 =
|
2 = 1/15
|
4. Beauty = 3 + 1 =
|
4 = 4/15
|
5. Bad = 0 + 1 =
|
1 = 1/15
|
6. Evil = 0 + 1 =
|
1 = 1/15
|
7. Devil = 0 + 1 =
|
1 = 1/15
|
8. Worst = 0 + 1 =
|
1 = 1/15
|
_________ +
Total = 15
Angka 15 didapatkan dari jumlah total kata. Terdapat kata-kata bernada negatif di kelas positif karena untuk menghasilkan akurasi yang tidak terlalu buruk saat melakukan pengujian pada data testing. Proses smoothing untuk kelas negatif tidak terlalu jauh berbeda, namun karena tidak ada kata positif maka jumlahnya bernilai 0 seperti berikut ini :
Negatif
1. Best = 0 + 1 =
|
1 = 1/16
|
2. Well = 0 + 1 =
|
1 = 1/16
|
3. Good = 0 + 1 =
|
1 = 1/16
|
4. Beauty = 0 + 1 =
|
1 = 4/16
|
5. Bad = 2 + 1 =
|
3 = 1/16
|
6. Evil = 1+ 1 =
|
2 = 1/16
|
7. Devil = 2 + 1 =
|
3 = 1/16
|
8. Worst = 3 + 1 =
|
4 = 1/16
|
_________ +
Total = 16
Sekarang masuk ke dalam proses klasifikasi jika ada dokumen yang berisi kalimat berikut ini “You are bad and you are good”. Untuk menggolongkan dokumen tersebut ke dalam sentimen positif dan negatif caranya dengan mengalikan hasil positif dokumen yaitu 4/7 dengan kemunculan kata bad 1/15 dan good 2/15 di kelas positif menjadi 4/7 x 1/15 * 2/15 = 0.571 * 0.066 * 0.133 =
0.005. Sedangkan untuk kelas negatif menjadi 3/7 x 1/16 * 3/16 = 0.428 * 0.062 * 0.187 = 0004.
Karena hasil positif lebih besar dari negatif maka dokumen termasuk ke dalam kelas positif. Saatnya masuk ke dalam pemrograman, kali ini menggunakan bahasa pemrograman Java dilakukan dengan langkah sebagai berikut.
- Buat urutan folder yang akan menampung data training dan testing.
Seperti pada gambar di bawah ini.
Gambar 18 : urutan folder yang akan menampung data training dan testing.
Kemudian pada folder data_training buat struktur folder seperti pada gambar di bawah ini.
Gambar 19 : folder klasifikasi
Untuk menampung data yang memiliki sentimen negatif dan positif. Sentimen didapatkan dengan cara intuisi kami misalkan terdapat banyak kata tidak baik dalam suatu artikel maka termasuk dalam dokumen bersentimen negatif. Dalam studi kasus pada tugas ini folder negatif berisi tentang berita negatif tentang pemain sepak bola.
- Buat program klasifikasi sentimen Naive Bayes menggunakan Java.
berfungsi untuk smoothing semua jumlah kata seperti pada gambar di bawah berikut :
Gambar 20 method class Word untuk smooting
Misalkan dalam dokumen pada data training berisi kalimat sebagai berikut :
“Hello world. You are good we are family”.
Kemudian buat kelas DocumentParser.java yang berfungsi untuk menghilangkan stopwords yaitu kata-kata yang tidak penting seperti “and, or, the” dan sebagainya, serta mengubah bentuk dokumen yang pada awalnya terdiri dari beberapa baris menjadi hanya 1 baris menggunakan string builder. Hal ini dikarenakan bahasa pemrograman java mengenali tipe data string dianggap hanya 1 baris. Dokumen secara otomatis dikenali sebagai tipe data string oleh bahasa pemrograman java. Gambar 21 berikut menjelaskan tentang deklarasi pembentukan variabel stopwords yang digunakan.


Gambar 21 : array stopwords
Kemudian untuk dapat memasukan stopwords kami membuat method untuk dapat memakai stopwords. Seperti gambar 22 dibawah ini :

Gambar 22 : method document parser.
Kemudian buat method untuk mengembalikan isi stopwords dan kalimat seperti pada gambar di bawah ini :

Gambar 23 : method kembalikan isi ke stopwords.
Kemudian buat fungsi untuk dapat membaca dokumen.
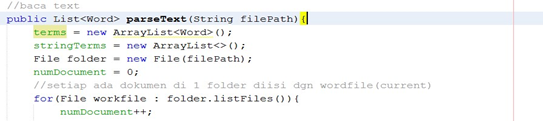
Gambar 24 : method untuk membaca dokumen.
Cara kerjanya yaitu misalkan setiap ada dokumen dalam 1 folder baik itu folder positif atau negatif maka akan masuk ke dalam current file.
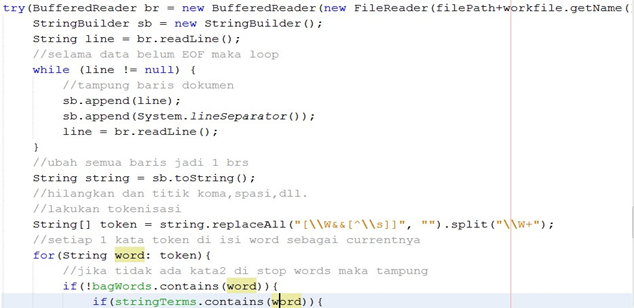
Gambar 25 : method untuk mengubah file ke bentuk stringbuilder.
Cara kerja potongan kode di atas adalah jika ada 2 dokumen dalam 1 folder yaitu D1 dan D2 maka file D1 terlebih dahulu yang dibaca kemudian isi file dijadikan bentuk stringbuilder contoh isi file seperti ini :
“Hello world. You are good. We are family”
Kemudian dengan stringbuilder(sb) bentuknya menjadi seperti ini :
Sb = “Hello world. You are good. We are family”
Kemudian masuk proses stopwords removal untuk menghilangkan kata-kata tidak penting.Sehingga variabel sb isinya menjadi berikut = “Hello world good. Family”. Setelah itu masuk proses tokenisasi yang bertujuan untuk menghilangkan spasi, titik, tanda petik, koma dan sebagainya sehingga dokumen dibaca menjadi kata per kata. Sehingga jadi seperti ini :
Negatif Token :
(0) = hello
(1) = world
(2) = good
Setelah itu masuk proses tampung kata positif seperti pada gambar di bawah ini :
 Gambar 26 : method untuk menampung kata positif.
Gambar 26 : method untuk menampung kata positif.
Masukkan token ke dalam tampung kata ke dalam golongan positif dokumen, kemudian setiap token ditambahkan dengan angka 1. Hal ini dilakukan untuk menghindari adanya bilangan 0 yang masuk ke dalam perhitungan. Karena jika ada, maka akan masuk dalam perhitungan naive bayes semua yang dibagi atau kali dengan 0, sehingga hasilnya 0 maka tidak sesuai dengan harapan. Selain itu dilakukan untuk mengantisipasi adanya kata negatif yang masuk ke dalam golongan positif pasti bernilai 0 maka wajib di smoothing supaya menambah nilai menjadi 1, proses ini berlaku juga untuk golongan kata negatif.
Positif Token :
(0) = hello + 1
(1) = world + 1 (2) = good + 1
Kemudian buat fungsi yang akan mengembalikan total jumlah dokumen telah diproses.

Gambar 27 : fungsi untuk mendapatkan total dokumen
Buat kelas main yang berfungsi sebagai pembaca data dan pemanggil semua kelas untuk dapat menghasilkan sentimen. Cara pengerjaannya :
1. Panggil kelas dokumen parser untuk dapat melakukan proses pembacaan dokumen, penghilangan stopwords dan menghilangkan tanda baca seperti gambar di bawah ini :

Gambar 28 : method main dari program
2. Looping sepanjang dokumen negatif, jika tidak ada kata negatif dalam dokumen positif maka masukan kata negatif ke dalam dokumen positif. Begitu sebaliknya jika looping dokumen positif seperti pada gambar di bawah ini :

Gambar 29 : method looping untuk sentiment analysis.
Buat kelas classification berfungsi untuk menggunakan metode naive bayes.
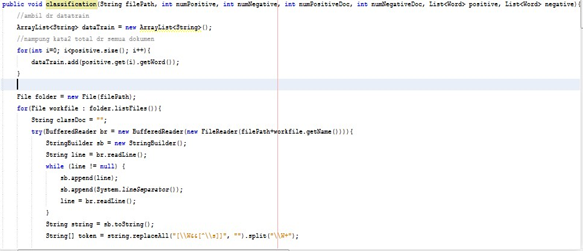
Gambar 30 : fungsi untuk mendapatkan total dokumen
Cara kerjanya yaitu :
1. Ambil semua dokumen dari data training.
2. Lakukan kembali tokenisasi.
3. Lakukan perhitungan untuk mengetahui total panjang dokumen positif/negatif seperti pada gambar di bawah ini :
Gambar 31 : method perhitungan total panjang dokumen.
4. Lakukan looping sepanjang token, jika tidak ada kalimat yang termasuk dalam stopwords maka lakukan naive bayes seperti pada gambar di bawah ini :

Gambar 32 : method looping untuk perhitungan naive bayes
Jika positif lebih besar dari negatif maka hasilnya akan positif.
- Studi Kasus Klasifikasi Sentimen Pemain Sepakbola Cristiano Ronaldo
Kami menggunakan 10 artikel berita data training yang terdiri dari kelas positif sejumlah 6 dan negatif sejumlah 4 berdasarkan judul berita bernada positif atau negatif. Data uji yang digunakan cukup 1 yaitu kelas positif ternyata hasil yang didapatkan akurat sama persis hasilnya positif seperti pada gambar berikut.
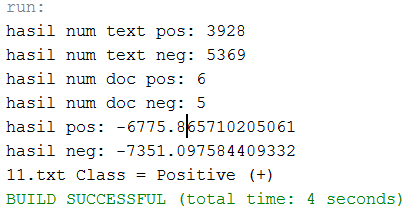
Gambar 33 : Hasil klasifikasi sentimen analisis Cristiano Ronaldo.
Kesimpulan
Dari hasil Named Entity Recognition yang hasilnya ditampilkan dalam bentuk Graph dari 11 artikel ternyata ketika masuk tahap klasifikasi sentimen menggunakan Naive Bayes Classifier hasil yang didapatkan yaitu Cristiano Ronaldo mendapatkan sentimen positif hal ini tidak terlepas dari lebih banyaknya jumlah artikel positif tentang Cristiano Ronaldo pada data training berjumlah 6 dibandingkan data training negatif sejumlah 4, Jadi selama data training positif lebih banyak dibandingkan negatif maka hasilnya akan selalu positif. Dapat disimpulkan bahwa dalam studi kasus ini mmembuktikan banyaknya hubungan entitas objek dalam hal ini Cristiano Ronaldo dengan entitas objek lainnya hasil sentimennya adalah positif.
Saran
Untuk pengembangan selanjutnya dibutuhkan suatu metode untuk memplotting langsung hasil Named Entity Recognition ke dalam Graph Selain itu juga perlu teknik pemrograman lain untuk dapat menghasilkan Klasifikasi sentimen dengan akurasi yang lebih baik jika perlu bisa memproses klasifikasi sentimen dari langsung dari hasil Graph untuk mempercepat proses komputasi jika misalnya artikel berjumlah lebih dari ribuan.
Kode dan berkas yang dibutuhkan dapat diunduh melalui tautan ini : https://drive.google.com/drive/folders/0B_8yM7uuxwRJcDNEc0ctUk15NEk?usp=sharing